

اکثر سیستمهای کامپیوتری دارای نوعی وضعیت هستند و به احتمال زیاد به یک سیستم ذخیرهسازی وابستهاند. دانش من در مورد پایگاههای داده به مرور زمان جمعآوری شده است، اما در طول مسیر اشتباهات طراحی ما منجر به از دست رفتن دادهها و قطعیها شد. در سیستمهای دادهمحور، پایگاههای داده در مرکز اهداف طراحی سیستم و موازنهها قرار دارند. با اینکه نمیتوان نحوه عملکرد پایگاههای داده را نادیده گرفت، مشکلاتی که توسعهدهندگان برنامه پیشبینی یا تجربه میکنند اغلب تنها بخش کوچکی از چالشها هستند. در این مجموعه، برخی از بینشهایی را که بهطور خاص برای توسعهدهندگانی که در این حوزه تخصص ندارند مفید یافتهام، به اشتراک میگذارم.
- شما خوششانس هستید اگر 99.999٪ مواقع شبکه مشکلی ایجاد نکند.
- ACID معانی متعددی دارد.
- هر پایگاه داده قابلیتهای متفاوتی در زمینه سازگاری و جداسازی دارد.
- قفلگذاری خوشبینانه گزینهای است وقتی نمیتوانید یک قفل نگه دارید.
- ناهنجاریهایی غیر از خواندن نادرست و از دست دادن دادهها وجود دارد.
- پایگاه داده من و من همیشه در ترتیب توافق نداریم.
- شاردینگ در سطح برنامه میتواند خارج از برنامه انجام شود.
- استفاده از AUTOINCREMENT میتواند مضر باشد.
- دادههای قدیمی میتوانند مفید و بدون قفل باشند.
- عدم هماهنگی ساعتها میان منابع مختلف ساعت اتفاق میافتد.
- زمان تأخیر معانی مختلفی دارد.
- الزامات عملکردی را برای هر تراکنش ارزیابی کنید.
- تراکنشهای تودرتو میتوانند مضر باشند.
- تراکنشها نباید وضعیت برنامه را حفظ کنند.
- Query planner اطلاعات زیادی درباره پایگاههای داده ارائه میدهد.
- مهاجرتهای آنلاین پیچیده اما ممکن هستند.
- رشد قابلتوجه پایگاه داده عدم قطعیت را افزایش میدهد.
شما خوششانس هستید اگر 99.999٪ مواقع شبکه مشکلی ایجاد نکند
این موضوع همچنان محل بحث است که شبکههای امروزی چقدر قابلاعتماد هستند و سیستمها چقدر اغلب به دلیل مشکلات شبکهای دچار قطعی میشوند. تحقیقات موجود محدود است و اغلب توسط سازمانهای بزرگی انجام میشود که شبکههای اختصاصی با سختافزار سفارشی و پرسنل متخصص دارند.
با دسترسی 99.999٪ به خدمات، گوگل گزارش داده است که تنها 7.6٪ از مشکلات اسپنر (Spanner)، پایگاه داده توزیعشده جهانی گوگل، ناشی از مشکلات شبکه است، هرچند این شرکت شبکه اختصاصی خود را دلیل اصلی این میزان دسترسی میداند. بررسیهای بیلیس (Bailis) و کینگزبری (Kingsbury) در سال 2014 یکی از فرضیههای محاسبات توزیعشده که توسط پیتر دویچ (Peter Deutsch) در سال 1994 مطرح شد را به چالش کشیده است. آیا واقعاً شبکه قابلاعتماد است؟
ما نظرسنجی جامعی خارج از سازمانهای بزرگ یا اینترنت عمومی در دست نداریم. همچنین داده کافی از ارائهدهندگان اصلی درباره میزان مشکلات مشتریانشان که به مشکلات شبکه مرتبط میشود وجود ندارد. گاهی قطعیهای شبکه در ارائهدهندگان بزرگ میتواند بخشهایی از اینترنت را برای ساعتها مختل کند، اما این موارد تنها رویدادهای پر سر و صدا هستند که تعداد زیادی از مشتریان قابل مشاهده تحت تأثیر قرار میگیرند. ممکن است مشکلات شبکه در موارد بیشتری اثرگذار باشند، حتی اگر همه این رویدادها سر و صدای زیادی ایجاد نکنند. مشتریان سرویسهای ابری نیز لزوماً دیدی نسبت به مشکلات خود ندارند. زمانی که قطعی رخ میدهد، شناسایی آن بهعنوان یک خطای شبکهای ناشی از ارائهدهنده ممکن نیست. برای آنها، خدمات شخص ثالث مانند جعبههای سیاه هستند. برآورد تأثیر بدون داشتن جایگاه یک ارائهدهنده اصلی ممکن نیست.
در مقایسه با گزارشهایی که بازیگران بزرگ درباره سیستمهای خود ارائه میدهند، شاید بتوان گفت شما خوششانس هستید اگر مشکلات شبکه تنها درصد کمی از مشکلات احتمالی شما که موجب قطعی میشود را تشکیل دهد. شبکه همچنان از مشکلات مرسوم مانند خرابی سختافزار، تغییرات توپولوژی، تغییرات پیکربندی مدیریتی و قطع برق رنج میبرد. اما اخیراً متوجه شدم که مشکلات جدیدی مانند گاز گرفتن کوسهها (بله، گاز گرفتن کوسهها) نیز واقعیت دارند.
ACID معانی متعددی دارد
ACID مخفف ویژگیهای اتمیک بودن، سازگاری، جداسازی و پایداری است. این ویژگیها تضمینهایی هستند که تراکنشهای پایگاه داده باید برای صحت دادهها حتی در شرایط خرابی، خطا، مشکلات سختافزاری و موارد مشابه به کاربران ارائه دهند. بدون ACID یا قراردادهای مشابه، توسعهدهندگان برنامه راهنمایی درباره مسئولیتهای خود در مقابل امکانات ارائهشده توسط پایگاه داده نداشتند. اکثر پایگاههای داده تراکنشی رابطهای سعی میکنند با ACID سازگار باشند، اما رویکردهای جدیدی مانند حرکت NoSQL منجر به ظهور بسیاری از پایگاههای داده بدون تراکنشهای ACID شدهاند، زیرا پیادهسازی آنها هزینهبر است.
وقتی تازه وارد این صنعت شده بودم، سرپرست فنی ما درباره اینکه آیا ACID مفهومی منسوخ شده است یا نه بحث میکرد. بهطور کلی میتوان گفت ACID بیشتر بهعنوان توصیفی کلی در نظر گرفته میشود تا یک استاندارد دقیق برای پیادهسازی. امروزه آن را بیشتر به این دلیل مفید میدانم که دستهای از مشکلات (و همچنین راهحلهای ممکن) را تعریف میکند.
همه پایگاههای داده با ACID سازگار نیستند و حتی در میان پایگاههای دادهای که ادعای سازگاری دارند، ACID میتواند بهطور متفاوتی تفسیر شود. یکی از دلایلی که ACID به شکلهای مختلف پیادهسازی میشود، تعداد موازنههای درگیر در پیادهسازی قابلیتهای ACID است. پایگاههای داده ممکن است خود را ACID معرفی کنند اما در شرایط خاص یا نحوه مدیریت رویدادهای “نادر” تفاسیر متفاوتی داشته باشند. توسعهدهندگان میتوانند حداقل در سطح کلی بیاموزند که پایگاههای داده چگونه کار میکنند تا درک درستی از حالتهای خرابی و موازنههای طراحی داشته باشند.
یکی از بحثهای شناختهشده این است که آیا MongoDB حتی پس از نسخه 4 واقعاً ACID است؟ MongoDB برای مدت طولانی از پشتیبانی journaling برخوردار نبود، هرچند بهطور پیشفرض دادهها را بیش از هر 60 ثانیه به دیسک ذخیره نمیکرد. به این سناریو توجه کنید: یک برنامه دو نوشتار (w1 و w2) انجام میدهد. MongoDB تغییر مربوط به نوشتار اول را ذخیره میکند، اما به دلیل خرابی سختافزاری نمیتواند نوشتار دوم را ذخیره کند.
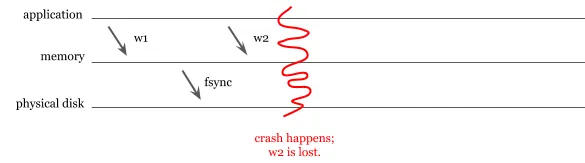
از دست رفتن دادهها در صورت خرابی MongoDB پیش از ذخیرهسازی به دیسک فیزیکی.
نوشتن به دیسک فرآیندی پرهزینه است و با اجتناب از این فرآیند، آنها ادعا میکردند که در نوشتن عملکرد بالایی دارند، در حالی که از پایداری دادهها چشمپوشی میکردند. امروزه MongoDB دارای journaling است، اما نوشتارهای نادرست همچنان میتوانند پایداری دادهها را تحت تأثیر قرار دهند، زیرا بهطور پیشفرض journalها را هر 100 میلیثانیه ذخیره میکند. همین سناریو همچنان برای پایداری journalها و تغییرات موجود در آنها ممکن است، هرچند خطر بهطور قابلتوجهی کاهش یافته است.
هر پایگاه داده قابلیتهای متفاوتی در زمینه سازگاری و جداسازی دارد.
در میان ویژگیهای ACID، سازگاری و جداسازی دارای گستردهترین طیف جزئیات پیادهسازی هستند، زیرا موازنههای بیشتری در این حوزه وجود دارد. قابلیتهای سازگاری و جداسازی هزینهبر هستند. این قابلیتها نیاز به هماهنگی دارند و برای حفظ سازگاری دادهها باعث افزایش رقابت میشوند. زمانی که مقیاسبندی افقی میان مراکز داده (بهویژه در مناطق جغرافیایی مختلف) انجام میشود، مشکلات بهطور قابلتوجهی پیچیدهتر میشوند. ارائه سطوح بالای سازگاری میتواند بسیار دشوار باشد زیرا دسترسی کاهش مییابد و تقسیمبندی شبکه بیشتر رخ میدهد. برای توضیح کلیتر این پدیده میتوانید به قضیه CAP مراجعه کنید. همچنین لازم به ذکر است که برخی برنامهها میتوانند مقداری ناسازگاری را مدیریت کنند یا برنامهنویسان ممکن است دیدگاه کافی درباره مشکل داشته باشند تا منطق اضافی در برنامه ایجاد کنند و بدون وابستگی زیاد به پایگاه داده آن را مدیریت کنند.
پایگاههای داده معمولاً لایههای مختلف جداسازی ارائه میدهند تا توسعهدهندگان بتوانند بر اساس موازنههای خود، گزینهای با کمترین هزینه را انتخاب کنند. جداسازی ضعیفتر ممکن است سریعتر باشد اما میتواند باعث بروز رقابت دادهای شود. جداسازی قویتر برخی از رقابتهای دادهای بالقوه را حذف میکند، اما کندتر است و ممکن است رقابتی ایجاد کند که پایگاه داده را تا حدی کند میکند که حتی باعث قطعی سیستم شود.
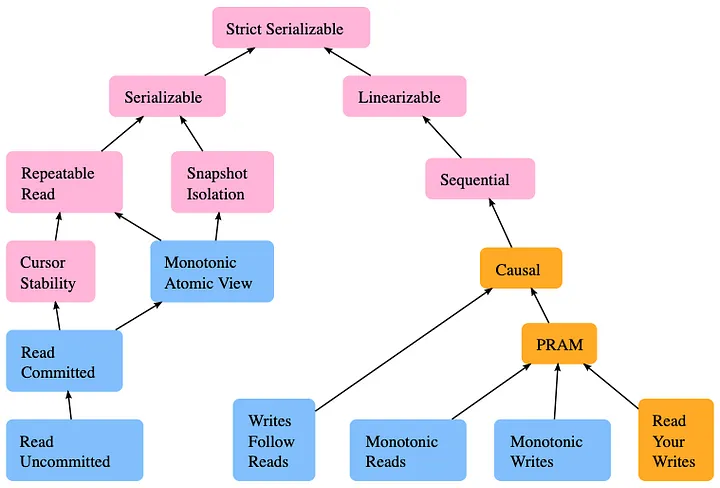
تصویری از مدلهای همزمانی موجود و روابط میان آنها.
استاندارد SQL تنها چهار سطح جداسازی را تعریف میکند، اگرچه بهطور نظری و عملی سطوح بیشتری نیز وجود دارد. وبسایت jepson.io دیدگاه کاملی از مدلهای همزمانی موجود ارائه میدهد که در صورت نیاز به مطالعه بیشتر مفید است. بهعنوان مثال، پایگاه داده اسپنر (Spanner) گوگل، همگامسازی ساعتی را تضمین میکند که یک لایه جداسازی سختگیرانهتر است، اما در لایههای استاندارد جداسازی SQL تعریف نشده است.
سطوح جداسازی تعریفشده در استاندارد SQL عبارتاند از:
- Serializable (سختگیرانهترین و پرهزینهترین): اجرای سریالپذیر تأثیری مشابه یک اجرای سریال از آن تراکنشها دارد. در اجرای سریال، هر تراکنش بهطور کامل اجرا میشود و سپس تراکنش بعدی آغاز میشود. نکتهای درباره سطح Serializable این است که اغلب بهعنوان “جداسازی تصویری” (مانند Oracle) پیادهسازی میشود، زیرا تفاوتهایی در تفسیر وجود دارد و “جداسازی تصویری” در استاندارد SQL نشان داده نشده است.
- Repeatable Reads: خواندنهای ثبتنشده در تراکنش فعلی برای همان تراکنش قابلمشاهده هستند، اما تغییراتی که توسط تراکنشهای دیگر انجام شده (مانند ردیفهای جدید درجشده) قابلمشاهده نیستند.
- Read Committed: خواندنهای ثبتنشده برای تراکنشها قابلمشاهده نیستند. تنها نوشتنهای ثبتشده قابلمشاهده هستند، اما خواندنهای شبحی ممکن است رخ دهند. اگر یک تراکنش دیگر ردیفهای جدیدی درج و ثبت کند، تراکنش فعلی میتواند هنگام پرسوجو آنها را مشاهده کند.
- Read Uncommitted (کمترین سختگیری و ارزانترین): خواندنهای نادرست مجاز است؛ تراکنشها میتوانند تغییراتی را که هنوز توسط تراکنشهای دیگر ثبت نشده است، مشاهده کنند. در عمل، این سطح میتواند برای بازگرداندن مقادیر تقریبی مانند پرسوجوهای COUNT(*) روی یک جدول مفید باشد.
سطح Serializable کمترین فرصتها را برای وقوع رقابت دادهای فراهم میکند، هرچند پرهزینهترین است و بیشترین رقابت را به سیستم تحمیل میکند. سایر سطوح جداسازی ارزانتر هستند اما احتمال رقابت دادهای را افزایش میدهند. برخی پایگاههای داده اجازه میدهند سطح جداسازی خود را تنظیم کنید، درحالیکه برخی دیگر دیدگاه قاطعتری دارند و لزوماً از همه سطوح پشتیبانی نمیکنند.
با اینکه پایگاههای داده حمایت خود از این سطوح جداسازی را تبلیغ میکنند، بررسی دقیق رفتار آنها ممکن است اطلاعات بیشتری درباره عملکرد واقعی آنها ارائه دهد.
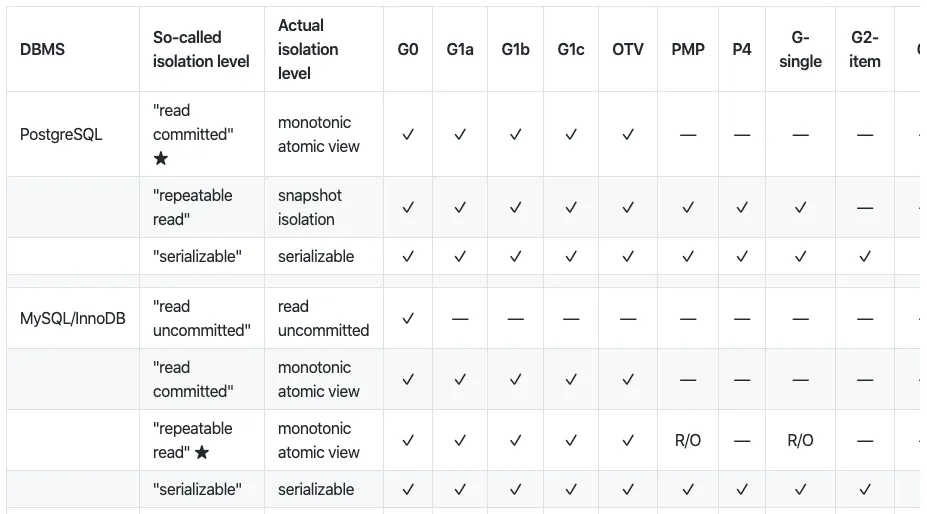
تصویری از ناهنجاریهای همزمانی در سطوح مختلف جداسازی در هر پایگاه داده.
“هرمیتج” (Hermitage) نوشته مارتین کِلِپمن (Martin Kleppmann) مروری بر ناهنجاریهای مختلف همزمانی و اینکه آیا یک پایگاه داده میتواند آن را در یک سطح جداسازی خاص مدیریت کند، ارائه میدهد. تحقیقات کِلِپمن نشان میدهد که چگونه سطوح جداسازی میتوانند توسط طراحان پایگاه داده بهطور متفاوتی تفسیر شوند.
زمانی که امکان نگهداشتن قفل وجود ندارد، قفلگذاری خوشبینانه یک گزینه است
قفلها میتوانند بسیار هزینهبر باشند، نهتنها به این دلیل که باعث رقابت بیشتر در پایگاه داده شما میشوند، بلکه ممکن است به اتصالهای پایدار از سرورهای برنامه به پایگاه داده نیاز داشته باشند. قفلهای انحصاری میتوانند بهطور قابلتوجهی تحت تأثیر تقسیمات شبکه قرار گیرند و باعث بروز بنبستهایی شوند که شناسایی و حل آنها دشوار است. در شرایطی که امکان نگهداشتن قفلهای انحصاری آسان نیست، قفلگذاری خوشبینانه یک گزینه محسوب میشود.
قفلگذاری خوشبینانه (Optimistic locking) روشی است که در آن هنگام خواندن یک ردیف، شماره نسخه، آخرین زمان تغییر یا چکسام (checksum) آن را ثبت میکنید. سپس میتوانید بهصورت اتمیک بررسی کنید که نسخه تغییری نکرده باشد، قبل از اینکه رکورد را تغییر دهید.
اگر اتمی بودن (atomicity) موردنیاز باشد (برای مثال همه عملیات یا بهطور کامل تأیید شوند یا لغو شوند) و ترتیب عملیات نیز مهم باشد، باید عملیاتهای T1 و T2 در یک تراکنش پایگاه داده واحد اجرا شوند.
شاردینگ در سطح برنامه میتواند خارج از برنامه نیز اجرا شود.
شاردینگ روشی برای تقسیم افقی پایگاه داده است. اگرچه برخی از پایگاه دادهها میتوانند دادهها را بهصورت خودکار بهصورت افقی تقسیم کنند، اما برخی دیگر یا قادر به این کار نیستند یا عملکرد خوبی در این زمینه ندارند. زمانی که معماران یا توسعهدهندگان داده بتوانند پیشبینی کنند که چگونه به دادهها دسترسی خواهد شد، ممکن است به جای واگذاری این کار به پایگاه داده، تقسیمبندی افقی را در سطح برنامه انجام دهند. این روش به شاردینگ در سطح برنامه (application-level sharding) معروف است.
نام شاردینگ در سطح برنامه اغلب این تصور اشتباه را ایجاد میکند که شاردینگ باید در سرویسهای برنامه اجرا شود. درحالیکه قابلیتهای شاردینگ میتوانند بهعنوان یک لایه در جلوی پایگاه داده پیادهسازی شوند. با توجه به رشد دادهها و تغییرات اسکیما، نیازهای شاردینگ ممکن است پیچیده شوند. توانایی ایجاد تغییر در استراتژیهای شاردینگ بدون نیاز به استقرار مجدد سرورهای برنامه میتواند بسیار مفید باشد.
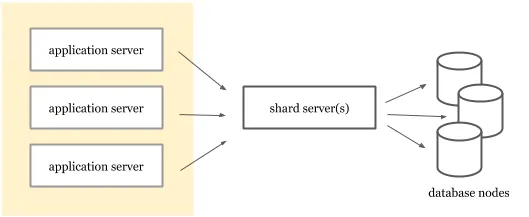
استفاده از شاردینگ بهعنوان یک سرویس جداگانه میتواند توانایی شما را در تغییر استراتژیهای شاردینگ بدون نیاز به استقرار مجدد برنامهها افزایش دهد. یکی از نمونههای شاردینگ در سطح برنامه، سیستم Vitess است. Vitess شاردینگ افقی را برای MySQL ارائه میدهد و به مشتریان این امکان را میدهد که از طریق پروتکل MySQL به آن متصل شوند. این سیستم دادهها را در میان گرههای MySQL که از وجود یکدیگر بیاطلاع هستند، شارد میکند.
استفاده از AUTOINCREMENT میتواند مضر باشد
استفاده از AUTOINCREMENT روش رایجی برای تولید کلیدهای اصلی (primary keys) است. در دنیای واقعی غیر معمول نیست که مواردی ببینیم که در آنها پایگاههای داده بهعنوان تولیدکننده شناسه (ID) استفاده میشوند و جداول مخصوص تولید شناسه در پایگاه داده وجود دارد. دلایلی وجود دارد که نشان میدهد تولید کلیدهای اصلی با روش افزایش خودکار ممکن است ایدهآل نباشد:
در سیستمهای پایگاه داده توزیعشده، افزایش خودکار یک مشکل پیچیده است.
برای تولید یک شناسه، به قفلگذاری سراسری نیاز است. اگر بتوانید از UUID استفاده کنید، نیازی به همکاری بین نودهای پایگاه داده نخواهید داشت. استفاده از افزایش خودکار با قفلگذاری ممکن است موجب ایجاد رقابت و کاهش قابل توجه عملکرد در عملیات درج در شرایط توزیعشده شود.برخی از پایگاه دادهها، الگوریتمهای پارتیشنبندی را بر اساس کلیدهای اصلی پیادهسازی میکنند.
شناسههای ترتیبی ممکن است باعث ایجاد نقاط داغ پیشبینینشده شوند و برخی از پارتیشنها را بیشازحد مشغول کنند، درحالیکه برخی دیگر بیکار باقی میمانند.سریعترین روش دسترسی به یک ردیف در پایگاه داده، استفاده از کلید اصلی آن است.
اگر روشهای بهتری برای شناسایی رکوردها دارید، شناسههای ترتیبی ممکن است مهمترین ستون جدول را به یک مقدار بیمعنی تبدیل کنند. در صورت امکان، از یک کلید اصلی طبیعی و جهانی منحصربهفرد (مانند نام کاربری) استفاده کنید.
پیش از تصمیمگیری، تأثیرات شناسههای افزایش خودکار در مقایسه با UUIDها را بر ایندکسگذاری، پارتیشنبندی و شاردینگ در نظر بگیرید و تصمیم بگیرید کدام گزینه برای شما مناسبتر است.
دادههای قدیمی میتوانند مفید و بدون نیاز به قفل باشند.
کنترل همزمانی چندنسخهای (MVCC) بسیاری از ویژگیهای سازگاری را که پیشتر بهطور مختصر بررسی کردیم، فراهم میکند. برخی از پایگاههای داده (مانند Postgres، Spanner) از MVCC استفاده میکنند تا هر تراکنش بتواند یک عکس لحظهای، یعنی نسخهای قدیمیتر از پایگاه داده را مشاهده کند. تراکنشهایی که روی این عکسهای لحظهای انجام میشوند، همچنان میتوانند برای سازگاری بهصورت سریالی باشند. زمانی که از یک عکس لحظهای قدیمی میخوانید، در واقع دادههای قدیمی میخوانید.
خواندن دادههای کمی قدیمی میتواند مفید باشد، بهویژه هنگامی که قصد تولید گزارشهای تحلیلی از دادههای خود یا محاسبه مقادیر تقریبی تجمعی را دارید.
اولین مزیت خواندن دادههای قدیمی، کاهش تأخیر است (بهویژه اگر پایگاه داده شما در میان مناطق جغرافیایی مختلف توزیع شده باشد). مزیت دوم یک پایگاه داده MVCC این است که به تراکنشهای فقطخواندنی اجازه میدهد بدون نیاز به قفل عمل کنند. این یک مزیت بزرگ در برنامههایی است که بیشتر به خواندن دادهها متکی هستند، اگر دادههای قدیمی قابل تحمل باشند.
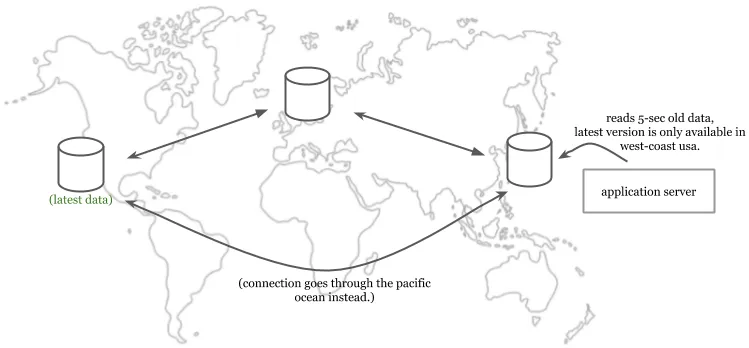
سرور برنامه میتواند دادههای قدیمی ۵ ثانیهای را از یک نسخه محلی بخواند، حتی اگر نسخه بهروز آن در سمت دیگر اقیانوس آرام در دسترس باشد.
پایگاههای داده نسخههای قدیمی را بهصورت خودکار پاکسازی میکنند و در برخی موارد به کاربران اجازه میدهند این کار را بهصورت دستی انجام دهند. برای مثال، Postgres به کاربران اجازه میدهد که VACUUM را بهصورت دستی انجام دهند، علاوه بر اینکه بهصورت خودکار نیز این کار را انجام میدهد. همچنین Spanner دارای یک جمعآوریکننده زباله (garbage collector) است که نسخههای قدیمیتر از یک ساعت را حذف میکند.
اختلافات زمانی میان منابع مختلف ساعت رخ میدهند.
یکی از اسرار پنهان دنیای کامپیوتر این است که همه APIهای مرتبط با زمان دروغ میگویند. ماشینهای ما نمیدانند زمان دقیق کنونی چیست. همه کامپیوترهای ما دارای یک کریستال کوارتز هستند که سیگنالی برای تعیین زمان تولید میکند. اما کریستالهای کوارتز نمیتوانند زمان را با دقت تعیین کنند و ممکن است سریعتر یا کندتر از ساعت واقعی عمل کنند. این انحراف میتواند تا ۲۰ ثانیه در روز باشد. زمان روی کامپیوترهای ما نیاز به همگامسازی با زمان واقعی هر چند وقت یکبار برای دقت بیشتر دارد.
سرورهای NTP برای همگامسازی استفاده میشوند، اما خود فرآیند همگامسازی ممکن است به دلیل شبکه به تأخیر بیفتد. اگر همگامسازی با یک سرور NTP در همان مرکز داده زمانبر باشد، همگامسازی با یک سرور عمومی NTP ممکن است تأخیر بیشتری ایجاد کند.
ساعتهای اتمی و GPS منابع بهتری برای تعیین زمان کنونی هستند، اما هزینهبر بوده و نیاز به تنظیمات پیچیدهای دارند که نمیتوان آنها را روی هر ماشینی نصب کرد. با توجه به این محدودیتها، در مراکز داده از یک رویکرد چندسطحی استفاده میشود. در حالی که ساعتهای اتمی و/یا GPS زمان دقیق را ارائه میدهند، زمان آنها از طریق سرورهای ثانویه به سایر ماشینها منتقل میشود. این بدان معناست که هر ماشین با مقداری انحراف از زمان واقعی مواجه خواهد بود.
و این پایان ماجرا نیست… برنامهها و پایگاههای داده اغلب در ماشینهای مختلف (و گاهی در مراکز مختلف) قرار دارند. نهتنها گرههای پایگاه داده که در چندین ماشین توزیع شدهاند نمیتوانند روی زمان به توافق برسند، بلکه ساعت سرور برنامه و گره پایگاه داده نیز همزمان نخواهند بود.
TrueTime شرکت Google در اینجا از یک رویکرد متفاوت پیروی میکند. بیشتر افراد فکر میکنند پیشرفت Google در زمینه ساعتها به استفاده از ساعتهای اتمی و GPS مربوط میشود، اما این تنها بخشی از ماجرا است. این همان کاری است که TrueTime انجام میدهد:
- TrueTime از دو منبع مختلف یعنی GPS و ساعتهای اتمی استفاده میکند. این ساعتها دارای حالتهای خطای متفاوتی هستند، بنابراین استفاده از هر دوی آنها قابلیت اطمینان را افزایش میدهد.
- TrueTime از یک API غیرمعمول استفاده میکند. این API زمان را بهصورت یک بازه ارائه میدهد. زمان ممکن است در هر نقطهای بین حد پایین و حد بالای این بازه باشد. پایگاه داده توزیعشده Google یعنی Spanner میتواند منتظر بماند تا اطمینان حاصل کند که زمان کنونی از یک زمان خاص گذشته است. این روش مقداری تأخیر به سیستم اضافه میکند، بهویژه زمانی که عدم قطعیت اعلامشده توسط سرورهای اصلی بالا باشد، اما در شرایط توزیع جهانی دقت را تضمین میکند.
اجزای Spanner از TrueTime استفاده میکنند، جایی که TT.now() یک بازه زمانی بازمیگرداند، بنابراین Spanner میتواند وقفههایی را تزریق کند تا اطمینان حاصل شود که زمان کنونی از یک نقطه زمانی خاص گذشته است.
با کاهش اطمینان در مورد زمان کنونی، عملیات Spanner ممکن است زمان بیشتری ببرد. به همین دلیل، حتی اگر داشتن ساعتهای دقیق غیرممکن باشد، حفظ اطمینان بالا برای عملکرد اهمیت دارد.
تاخیر معانی مختلفی دارد.
اگر از ده نفر در یک اتاق بپرسید «تاخیر» به چه معناست، ممکن است هرکدام پاسخ متفاوتی بدهند. در پایگاههای داده، تاخیر اغلب به «تاخیر پایگاه داده» اشاره دارد، اما این همان تاخیری نیست که کاربر تجربه میکند. کاربر تاخیر پایگاه داده و تاخیر شبکه را با هم احساس میکند. توانایی تشخیص میان تاخیر کاربر و تاخیر پایگاه داده در هنگام رفع مشکلات بحرانی بسیار اهمیت دارد. هنگام جمعآوری و نمایش شاخصها، همیشه داشتن هر دو نوع تاخیر را در نظر بگیرید.
نیازمندیهای عملکردی را برای هر تراکنش ارزیابی کنید.
گاهی اوقات پایگاههای داده ویژگیها و محدودیتهای عملکردی خود را بهصورت توان عملیاتی و تاخیر در نوشتن و خواندن بیان میکنند. اگرچه این اطلاعات میتواند دیدی کلی از محدودیتهای اصلی ارائه دهد، اما برای ارزیابی عملکرد یک پایگاه داده جدید، رویکرد جامعتر این است که عملیاتهای کلیدی (بهازای هر پرسوجو یا تراکنش) را جداگانه بررسی کنید. مثالها:
- توان عملیاتی و تاخیر نوشتن هنگام درج یک سطر جدید در جدول X (با ۵۰ میلیون سطر) با محدودیتهای داده شده و پر کردن سطرها در جداول مرتبط.
- تاخیر هنگام پرسوجوی دوستانِ دوستان یک کاربر وقتی تعداد متوسط دوستان ۵۰۰ نفر است.
- تاخیر در بازیابی ۱۰۰ رکورد برتر برای تایملاین کاربر وقتی کاربر به ۵۰۰ حساب کاربری که هر ساعت X ورودی دارند، مشترک است.
ارزیابی و آزمایش میتواند شامل چنین موارد کلیدی باشد تا زمانی که مطمئن شوید یک پایگاه داده میتواند نیازهای عملکردی شما را برآورده کند. یک قاعده مشابه این است که هنگام جمعآوری شاخصهای تاخیر و تنظیم SLOها نیز این تفکیک را در نظر بگیرید.
هنگام جمعآوری شاخصها به ازای هر عملیات، مراقب تعداد زیاد مقادیر منحصربهفرد (cardinality) باشید. اگر به دادههای اشکالزدایی با مقادیر منحصربهفرد بالا نیاز دارید، از لاگها، جمعآوری رویدادها یا ردیابی توزیعشده استفاده کنید. برای آشنایی با روشهای اشکالزدایی تاخیر، به «میخواهید تاخیر را اشکالزدایی کنید؟» مراجعه کنید.
تراکنشهای تو در تو میتوانند مضر باشند.
همه پایگاههای داده از تراکنشهای تو در تو پشتیبانی نمیکنند، اما زمانی که این امکان وجود داشته باشد، تراکنشهای تو در تو میتوانند باعث ایجاد خطاهای برنامهنویسی شوند که شناسایی آنها همیشه آسان نیست، تا زمانی که مشخص شود با موارد غیرعادی روبهرو هستید.
اگر میخواهید از تراکنشهای تو در تو اجتناب کنید، کتابخانههای مشتری میتوانند وظیفه شناسایی و جلوگیری از آنها را بر عهده بگیرند. اگر نمیتوانید از آنها اجتناب کنید، باید دقت کنید که در موقعیتهای غیرمنتظرهای قرار نگیرید که در آنها تراکنشهای تأییدشده بهدلیل یک تراکنش فرزند بهطور ناخواسته لغو شوند.
کپسولهسازی تراکنشها در لایههای مختلف میتواند به بروز موارد غیرمنتظره در تراکنشهای تو در تو منجر شود و از دیدگاه خوانایی، ممکن است درک هدف کد دشوار باشد. به برنامه زیر نگاهی بیندازید: