

ایندکسهای ترکیبی که به عنوان ایندکسهای چند ستونی نیز شناخته میشوند، تقریباً ۱۰ برابر سریعتر از ادغام ایندکسها هستند. در PostgreSQL، این تفاوت بیشتر از MySQL است زیرا PostgreSQL از اسکنهای فقط ایندکس برای کوئریهایی که شامل ادغام ایندکسها میشوند، پشتیبانی نمیکند.
در حین کار با Readwise (ریدوایز) برای بهینهسازی پایگاه داده آنها به منظور راهاندازی قریبالوقوع محصول Reader (ریدِر)، از خودم پرسیدم: ایندکس ترکیبی چقدر سریعتر از اجازه دادن به پایگاه داده برای انجام ادغام ایندکسها از چند ایندکس مختلف است؟ به این کوئری توجه کنید:
SELECT count(*) /* matches ~100 rows out of 10M */
FROM table
WHERE int1000 = 1 AND int100 = 1
/* int100 rows are 0..99 and int1000 0...9999 */
ما میتوانیم یک ایندکس ترکیبی بر روی (int1000, int100) بسازیم، یا اینکه دو ایندکس جداگانه بر روی (int1000) و (int100) داشته باشیم و به پایگاه داده اجازه دهیم که از هر دو ایندکس استفاده کند.
داشتن یک ایندکس ترکیبی سریعتر است، اما چقدر سریعتر از دو ایندکس جداگانه؟ بیایید محاسبات اولیه را انجام دهیم و سپس آن را در PostgreSQL و MySQL تست کنیم.
محاسبات اولیه
ما با محاسبات اولیه شروع میکنیم و سپس آن را در برابر PostgreSQL و MySQL بررسی میکنیم.
ایندکس ترکیبی: ~۱ میلیثانیه
ایندکس ایدهآل برای این count(*) به شکل زیر است:
CREATE INDEX ON table (int1000, int100)
این ایندکس امکان انجام کل شمارش را در این یک ایندکس فراهم میکند.
WHERE int1000 = 1 AND int100 = 1 تقریباً ۱۰۰ رکورد از مجموع ۱۰ میلیون رکورد جدول را تطابق میدهد. پایگاه داده جستجوی سریعی در درخت ایندکس انجام میدهد تا به برگهایی برسد که در آنها هر دو ستون برابر با ۱ هستند، سپس تا جایی که شرایط دیگر برقرار نباشد، به اسکن ادامه میدهد.
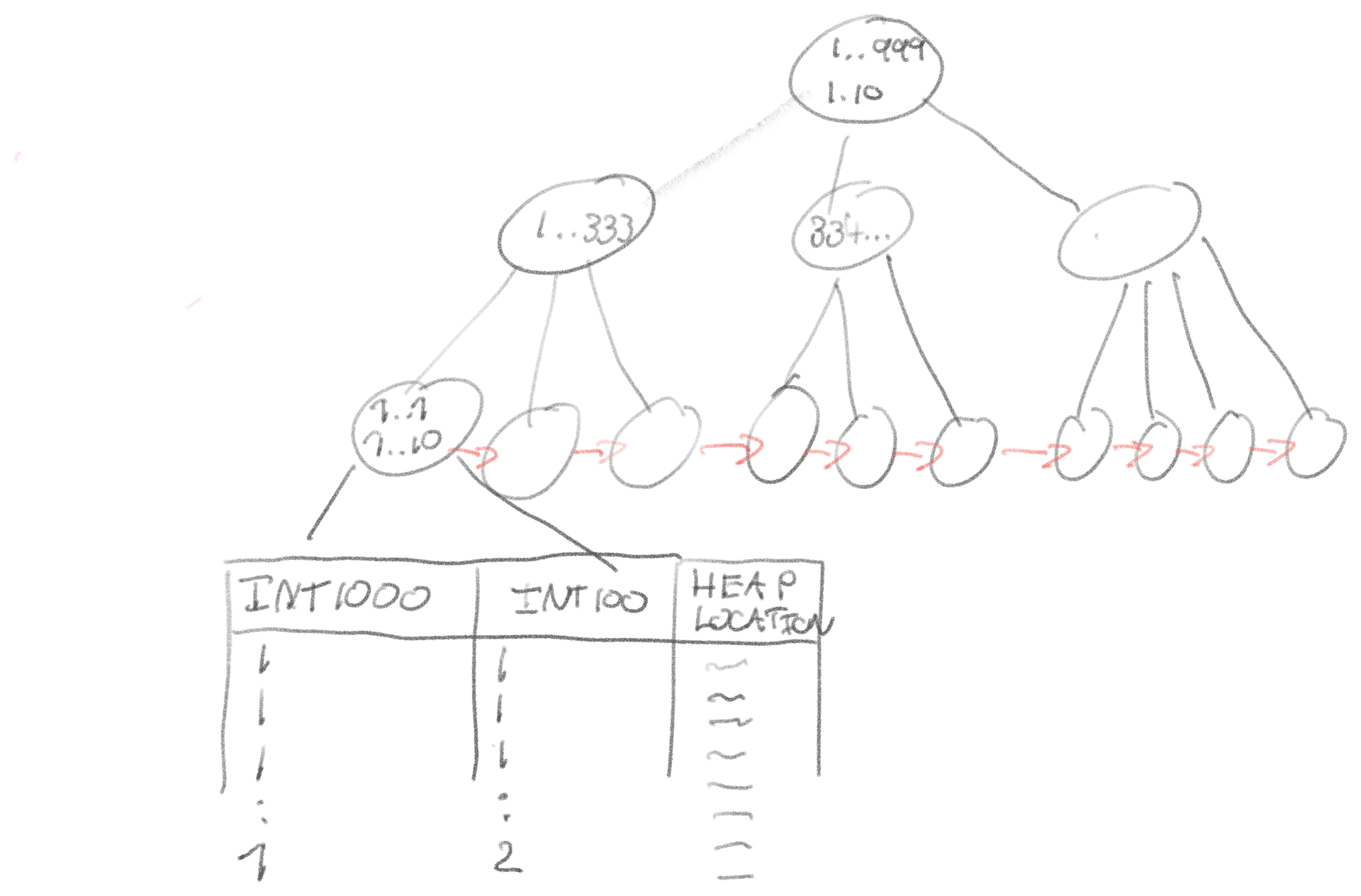
برای این ورودیهای ۶۴ بیتی ایندکس، ما انتظار داریم که فقط ~۱۰۰ ورودی که تطابق دارند اسکن شود که معادل تقریباً ~۲ کیلوبایت است. طبق مرجع محاسباتی، میتوانیم ۱ میگابایت را در ۱۰۰ میکروثانیه از حافظه بخوانیم، بنابراین این کار عملاً زمان زیادی نمیبرد. با در نظر گرفتن هزینههای کوئری، ناوبری در درخت ایندکس و سایر عوامل، از نظر تئوری باید هیچ پایگاه دادهای بیشتر از ۱۰۰ تا ۵۰۰ میکروثانیه زمان برای انجام این کوئری با ایندکس ترکیبی نیاز نداشته باشد.
ادغام ایندکس: ~۱۰-۳۰ میلیثانیه
اما پایگاه داده میتواند همچنین یک ادغام ایندکس از دو ایندکس جداگانه انجام دهد:
CREATE INDEX ON table (int1000)
CREATE INDEX ON table (int100)
اما پایگاه داده چگونه از دو ایندکس استفاده میکند؟ و این ادغام ممکن است چقدر هزینهبر باشد؟
نحوه تقاطع ایندکسها بستگی به پایگاه داده دارد! روشهای مختلفی برای یافتن تقاطع دو لیست بدون ترتیب وجود دارد: هشینگ، مرتبسازی، مجموعهها، درختهای KD، نقشههای بیت، …
MySQL آنچه را که «تقاطع ادغام ایندکس» مینامد، انجام میدهد. من به منابع مراجعه نکردهام، اما احتمالاً این کار با مرتبسازی انجام میشود. در مقابل، Postgres تقاطع ایندکسها را با تولید یک نقشه بیت بعد از اسکن هر ایندکس انجام میدهد و سپس آنها را با عمل AND ترکیب میکند.
int100 = 1 حدوداً ۱۰M*1/1000≈100,000 رکورد را برمیگرداند که تقریباً ~۱.۵ مگابایت برای اسکن کردن است. int1000 = 1 فقط ~۱۰،۰۰۰ رکورد را تطابق میدهد، بنابراین در مجموع حدود ۲۰۰ میکروثانیه از حافظه هر دو ایندکس خوانده میشود.
بعد از بهدست آوردن تطابقها از ایندکسها، باید آنها را تقاطع کنیم. در اینجا، بهسادگی و برای راحتی محاسبات اولیه، فرض میکنیم که تطابقها را از هر دو ایندکس مرتب کرده و سپس متقاطع میکنیم.
ما میتوانیم ۱ میگابایت را در ۵ میلیثانیه مرتب کنیم. بنابراین حدوداً ۱۰ میلیثانیه زمان میبرد تا آن را مرتب کنیم، از هر دو لیست مرتبشده عبور کنیم، برای خواندن ~۲۰۰ میکروثانیه از حافظه، تقاطع را در حافظه بنویسیم و سپس تقاطع را بهدست آوریم، یعنی رکوردهایی که هر دو شرط را تطابق میدهند.
پس محاسبات اولیه ما نشان میدهد که برای دو ایندکس جداگانه انتظار داریم کوئری حدوداً ۱۰ میلیثانیه زمان ببرد. مرتبسازی حساس به اندازه ایندکس است که تقریباً تخمینی است، بنابراین یک ضریب کم به آن میدهیم تا در نهایت ~۱۰-۳۰ میلیثانیه بدست آوریم.
همانطور که دیدیم، تقاطع هزینهای معنادار دارد و در کاغذ انتظار داریم که تقریباً یک مرتبه کندتر از ایندکسهای ترکیبی باشد. با این حال، ۱۰ میلیثانیه هنوز در بسیاری از موقعیتها منطقی است و بسته به شرایط ممکن است خوشایند باشد که برای کوئری ایندکس ترکیبی خاصی نداشته باشیم! برای مثال، اگر شما اغلب بین مجموعهای از ۱۰ها ستون join میکنید.
واقعیت
حالا که انتظارات خود را از اصول اولیه در مقایسه ایندکسهای ترکیبی و ادغام چند ایندکس تنظیم کردهایم، بیایید ببینیم که PostgreSQL (پستگرس) و MySQL (مایاسکیوال) در دنیای واقعی چگونه عمل میکنند.
ایندکس ترکیبی: ۵ میلیثانیه ✅
هم MySQL و هم Postgres بعد از ایجاد ایندکس، اسکنهای فقط ایندکس انجام میدهند:
/* 10M rows total, int1000 = 1 matches ~10K, int100 matches ~100K */
CREATE INDEX ON table (int1000, int100)
EXPLAIN ANALYZE SELECT count(*) FROM table WHERE int1000 = 1 AND int100 = 1
/* postgres, index is ~70 MiB */
Aggregate (cost=6.53..6.54 rows=1 width=8) (actual time=0.919..0.919 rows=1 loops=1)
-> Index Only Scan using compound_idx on test_table (cost=0.43..6.29 rows=93 width=0) (actual time=0.130..0.909 rows=109 loops=1)
Index Cond: ((int1000 = 1) AND (int100 = 1))
Heap Fetches: 0
/* mysql, index is ~350 MiB */
-> Aggregate: count(0) (cost=18.45 rows=1) (actual time=0.181..0.181 rows=1 loops=1)
-> Covering index lookup on test_table using compound_idx (int1000=1, int100=1) (cost=9.85 rows=86) (actual time=0.129..0.151 rows=86 loops=1)
هرکدام حدوداً ۳-۵ میلیثانیه زمان میبرند وقتی که ایندکس در کش باشد. این کمی کندتر از ~۱ میلیثانیهای است که از محاسبات اولیه انتظار داشتیم، اما در تجربه ما با محاسبات اولیه در پایگاه داده، این در حدود یک مرتبه از نظر مقیاس منطقی به نظر میرسد. ما این را به هزینههای اضافی در عبور از ایندکس نسبت میدهیم.
ادغام ایندکس
MySQL: ۳۰-۴۰ میلیثانیه ✅
زمانی که کوئری را در MySQL اجرا میکنیم، حدوداً ۳۰-۴۰ میلیثانیه زمان میبرد که بهخوبی با انتهای بالای محاسبات اولیه ما مطابقت دارد. این به این معناست که درک ما از اصول اولیه احتمالاً با واقعیت همراستا است!
بیایید بررسی کنیم که آیا پایگاه داده همانطور که انتظار داشتیم عمل میکند با نگاه به طرح کوئری:
/* 10M rows total, int1000 = 1 matches ~10K, int100 matches ~100K */
EXPLAIN ANALYZE SELECT count(*) FROM table WHERE int1000 = 1 AND int100 = 1
/* mysql, each index is ~240 MiB */
-> Aggregate: count(0) (cost=510.64 rows=1) (actual time=31.908..31.909 rows=1 loops=1)
-> Filter: ((test_table.int100 = 1) and (test_table.int1000 = 1)) (cost=469.74 rows=409) (actual time=5.471..31.858 rows=86 loops=1)
-> Intersect rows sorted by row ID (cost=469.74 rows=410) (actual time=5.464..31.825 rows=86 loops=1)
-> Index range scan on test_table using int1000 over (int1000 = 1) (cost=37.05 rows=18508) (actual time=0.271..2.544 rows=9978 loops=1)
-> Index range scan on test_table using int100 over (int100 = 1) (cost=391.79 rows=202002) (actual time=0.324..24.405 rows=99814 loops=1)
/* ~30 ms */
طرح کوئری MySQL به ما میگوید که دقیقاً همانطور که انتظار داشتیم عمل میکند: از هر ایندکس، ورودیهای تطابقی را میگیرد، آنها را با هم تقاطع میکند و شمارش را بر روی تقاطع انجام میدهد. با اجرای EXPLAIN بدون آنالیز میتوانم تایید کنم که همهچیز از ایندکس سرو میشود و هیچوقت به جستجوی ردیف کامل نمیرود.
Postgres: ۲۵-۹۰ میلیثانیه 🤔
Postgres هم در حدود یک مرتبه از محاسبات اولیه ما است، اما در رده بالاتر با تغییرات بیشتر عمل میکند و بهطور کلی عملکرد ضعیفتری نسبت به MySQL دارد. آیا تقاطع مبتنی بر نقشه بیت در این کوئری کندتر است؟ یا اینکه چیزی کاملاً متفاوت از MySQL انجام میدهد؟
بیایید به طرح کوئری نگاه کنیم با استفاده از همان کوئری که از MySQL استفاده کردیم:
/* 10M rows total, int1000 = 1 matches ~10K, int100 matches ~100K */
EXPLAIN ANALYZE SELECT count(*) FROM table WHERE int1000 = 1 AND int100 = 1
/* postgres, each index is ~70 MiB */
Aggregate (cost=1536.79..1536.80 rows=1 width=8) (actual time=29.675..29.677 rows=1 loops=1)
-> Bitmap Heap Scan on test_table (cost=1157.28..1536.55 rows=95 width=0) (actual time=27.567..29.663 rows=109 loops=1)
Recheck Cond: ((int1000 = 1) AND (int100 = 1))
Heap Blocks: exact=109
-> BitmapAnd (cost=1157.28..1157.28 rows=95 width=0) (actual time=27.209..27.210 rows=0 loops=1)
-> Bitmap Index Scan on int1000_idx (cost=0.00..111.05 rows=9948 width=0) (actual time=2.994..2.995 rows=10063 loops=1)
Index Cond: (int1000 = 1)
-> Bitmap Index Scan on int100_idx (cost=0.00..1045.94 rows=95667 width=0) (actual time=23.757..23.757 rows=100038 loops=1)
Index Cond: (int100 = 1)
Planning Time: 0.138 ms
/* ~30-90ms */
طرح کوئری تایید میکند که از استراتژی تقاطع نقشه بیت برای تقاطع دو ایندکس استفاده میکند. اما این دلیل اصلی تفاوت عملکرد نیست.
در حالی که MySQL تمام تجمیع (count(*)) را از ایندکس سرو میکند، Postgres در واقع برای هر ردیف به هیپ (heap) میرود. هیپ شامل تمام ردیف است که بالای ۱ کیلوبایت است. این هزینهبر است و زمانی که کش هیپ گرم نباشد، کوئری تقریباً ۱۰۰ میلیثانیه زمان میبرد!
همانطور که از طرح کوئری مشخص است، به نظر میرسد که Postgres نمیتواند اسکنهای تنها ایندکس را همراه با تقاطع ایندکسها انجام دهد. شاید در نسخههای آینده Postgres این قابلیت را اضافه کنند؛ من هیچ دلیل بنیادی نمیبینم که چرا نتوانند این کار را انجام دهند!
رفتن به هیپ تأثیر زیادی ندارد وقتی فقط برای ۱۰۰ رکورد به هیپ میرویم، بهویژه وقتی که کش باشد. اما اگر شرط را به WHERE int10 = 1 and int100 = 1 تغییر دهیم و در مجموع ۱۰،۰۰۰ تطابق داشته باشیم، در Postgres این کوئری ۷ ثانیه زمان میبرد، در حالی که در MySQL که اسکن تنها ایندکس روشن است، ۲۰۰ میلیثانیه است!
بنابراین MySQL در زمانی که بتوان تنها از ایندکس برای کل کوئری استفاده کرد، در ادغام ایندکسها برتری دارد. اما باید اشاره کنیم که حداقل زمان Postgres وقتی که همهچیز در کش باشد برای این اندازه تقاطع خاص، پایینتر است و احتمالاً تقاطع مبتنی بر نقشه بیت آن سریعتر است.
اما از نظر اسکنهای تنها ایندکس، Postgres و MySQL عملکرد تقریبا معادل دارند. برای مثال، اگر ما از شرط int10 = 1 استفاده کنیم، Postgres اسکن تنها ایندکس را انجام میدهد چون فقط یک ایندکس دخیل است.
اولین باری که من Postgres را برای این اسکن فقط ایندکس اجرا کردم، بیش از یک ثانیه زمان میبرد، مجبور شدم برای اینکه عملکرد مطابقت کند، VACUUM اجرا کنم! اسکنهای تنها ایندکس نیاز به اجرای مکرر VACUUM دارند تا از رفتن به هیپ برای دریافت ردیف کامل در Postgres جلوگیری کنند.
VACUUM کمک میکند زیرا Postgres باید به هیپ مراجعه کند برای هر رکوردی که از آخرین VACUUM تغییر کرده است، به دلیل پیادهسازی MVCC آن. از نظر من، اگر جدول شما پر از بهروزرسانی باشد و VACUUM پرهزینه باشد، این میتواند عواقب جدی برای اسکنهای تنها ایندکس داشته باشد.
نتیجهگیری
ادغام ایندکسها تقریباً 10 برابر کندتر از ایندکسهای ترکیبی هستند زیرا تقاطعهای تصادفی عملیاتی بسیار سریع نیستند. این عملیات به طور مثال نیاز به مرتبسازی خروجی هر اسکن ایندکس برای حل این مشکل دارد. ایندکسها میتوانند برای تقاطع بیشتر بهینهسازی شوند، اما این احتمالاً تأثیرات دیگری بر بار پایدار خواهد داشت.
اگر میپرسید آیا باید یک ایندکس ترکیبی اضافه کنید، یا میتوانید با ایجاد دو ایندکس جداگانه و اتکا به پایگاه داده برای استفاده از هر دو ایندکس پیش بروید — قانون سرانگشتی که ما تعیین کردهایم این است که ادغام ایندکسها تقریباً 10 برابر کندتر از ایندکس ترکیبی خواهد بود. با این حال، در بیشتر موارد، این زمان کمتر از 100 میلیثانیه خواهد بود، به شرطی که شما بر روی صدها ردیف عمل کنید (در یک پایگاه داده عملیاتی رابطهای، امیدواریم که بیشتر مواقع همینطور باشد).
فاصله در عملکرد زمانی بیشتر خواهد شد که با بیشتر از دو ستون تقاطع ایجاد کنید، و با اندازه تقاطع بزرگتر — من مجبور شدم محدوده این مقاله را جایی محدود کنم. به طور تقریبی یک ترتیب اندازه منطقی به نظر میرسد، با حدود 100 ردیف که با میانگینهای بسیاری از کوئریهای دنیای واقعی مطابقت دارند.
اگر از Postgres استفاده میکنید، مراقب باشید که به ادغام ایندکسها تکیه کنید! Postgres پس از ادغام ایندکسها اسکنهای فقط ایندکس را انجام نمیدهد و نیاز به مراجعه به هِیپ برای تعداد زیادی از رکوردها (count(*)) دارد. اگر فقط 10ها تا 100ها ردیف باز میگردانید، معمولاً این مشکلی نخواهد بود.
یک نکته دیگر: اگر در وضعیتی هستید که دهها ستون با ترکیبهای مختلف فیلتر میکنند، با کوئریهایی مثل این:
SELECT id
FROM products
WHERE color=blue AND type=sneaker AND activity=training
AND season=summer AND inventory > 0 AND price <= 200 AND price >= 100
/* and potentially many, many more rules */
در این صورت، با Postgres/MySQL کمی در موقعیت دشواری قرار دارید. برای پشتیبانی مناسب از این مورد استفاده، به انفجار ترکیبی ایندکسهای ترکیبی نیاز خواهید داشت که برای عملکرد زیر 10 میلیثانیه که برای وبسایتهای سریع ضروری است، حیاتی است. این واقعاً غیرعملی است.
متأسفانه، برای زمانهای پاسخ زیر 10 میلیثانیه، نمیتوانیم به ادغام ایندکسها اعتماد کنیم که آنقدر سریع باشند، به دلیل تقاطعهای تصادفی. من مقالهای نوشتم درباره حل مشکل کوئریهایی که شرایط زیادی دارند با استفاده از Lucene، که در انجام تقاطعهای زیادی بسیار خوب است. جالب خواهد بود که این را با ایندکسهای GIN (ایندکس معکوس، مشابه با چیزی که Lucene انجام میدهد) در Postgres امتحان کنیم و مقایسهای داشته باشیم. ایندکسهای Bloom نیز ممکن است برای این کار مناسب باشند. پایگاه دادههای ستونی شاید در این زمینه بهتر باشند، اما هنوز به طور عمیق به آن نگاه نکردهام.