

برخی پایگاههای داده مانند Microsoft SQL Server، IBM Db2 و همچنین PostgreSQL از نسخه ۱۱ به بعد، یک عبارت include را در دستور create index ارائه میدهند. اضافه شدن این ویژگی به PostgreSQL بهانه ارائه این توضیح طولانی و دیرهنگام درباره عبارت include است.
پیش از ورود به جزئیات، بیایید با یک مرور کوتاه درباره نحوه کار ایندکسهای B-tree (غیر خوشهای) و اسکن تنها ایندکس (index-only scan) آغاز کنیم.
مرور: ایندکسهای B-tree
برای درک عبارت include، ابتدا باید بدانید که استفاده از یک ایندکس میتواند تا سه لایه از ساختارهای داده را تحت تأثیر قرار دهد:
- B-tree
- لیست پیوندی دوطرفه در سطح نود برگ B-tree
- جدول
دو ساختار اول با هم یک ایندکس را تشکیل میدهند، بنابراین میتوان آنها را به یک واحد ترکیب کرد، یعنی “ایندکس B-tree”. با این حال، ترجیح میدهم آنها را جداگانه بررسی کنم، زیرا نیازهای متفاوتی را برآورده میکنند و تأثیرات متفاوتی بر عملکرد دارند. علاوه بر این، توضیح عبارت include نیازمند این تمایز است.
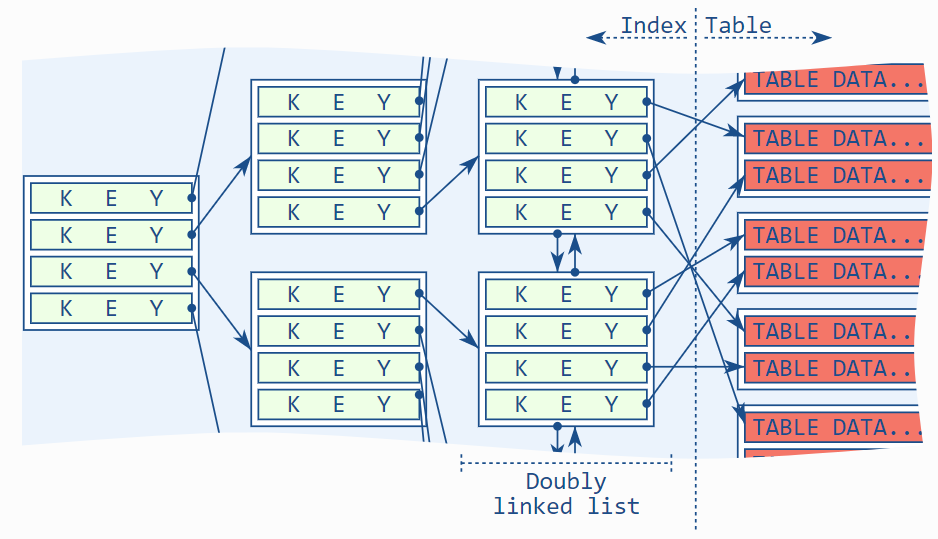
به طور کلی، نرمافزار پایگاه داده ابتدا با پیمایش B-tree اولین مقدار دارای تطابق را در سطح نود برگ پیدا میکند (۱). سپس لیست پیوندی دوطرفه را دنبال میکند تا تمام واردههای مطابق را پیدا کند (۲) و در نهایت هر یک از این ورودیهای مطابق را از جدول بازیابی میکند (۳). در واقع، دو مرحله آخر میتوانند با هم انجام شوند، اما این برای درک مفهوم کلی اهمیت ندارد.
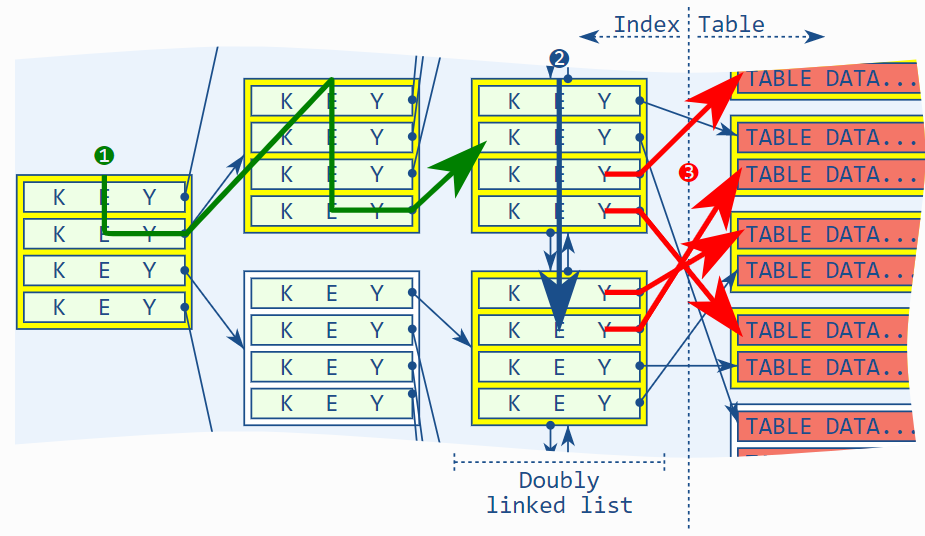
فرمولهای زیر به شما ایدهای تقریبی از تعداد عملیاتهای خواندن موردنیاز هر یک از این مراحل میدهند. مجموع این سه مؤلفه، میزان کار برای دسترسی به ایندکس را نشان میدهد:
- B-tree:
log100(<تعداد رکوردها در جدول>)، که معمولاً کمتر از ۵ است - لیست پیوندی دوطرفه: <تعداد رکوردهای خوانده شده از ایندکس> / 100
- جدول: <تعداد رکوردهای خوانده شده از جدول>
هنگام بارگذاری تعداد کمی رکورد، B-tree بیشترین سهم را در مقدار کار کلی دارد. به محض اینکه نیاز باشد تنها چند رکورد از جدول بازیابی شوند، این مرحله پیشی میگیرد. در هر دو حالت—چه تعداد کم و یا زیاد رکورد—لیست پیوندی دوطرفه معمولاً عامل جزئی است، زیرا رکوردهای با مقادیر مشابه را در کنار یکدیگر ذخیره میکند، بهطوریکه یک عملیات خواندن میتواند ۱۰۰ یا حتی بیشتر رکورد را بازیابی کند. این فرمول این موضوع را با مقسومعلیه مربوطه نشان میدهد.
ایده کلی و اصلی بهینهسازی این است که با انجام کار کمتر، به همان هدف برسیم. وقتی صحبت از دسترسی به ایندکس میشود، این بدان معناست که نرمافزار پایگاه داده اگر نیازی به بعضی دادهها نداشته باشد، از دسترسی به آن ساختار داده صرف نظر میکند.
در مورد شیوه کار ایندکس B-tree میتوانید فصل ۱ «Anatomy of an SQL Index» در SQL Performance Explained را بخوانید
مرور: اسکن تنها ایندکس
اسکن تنها ایندکس (Index-only scan) دقیقاً همین کار را انجام میدهد: اگر دادههای موردنیاز در لیست پیوندی دوطرفه ایندکس موجود باشند، دسترسی به جدول را حذف میکند.
به ایندکس و پرسوجوی زیر توجه کنید که از مقاله “Index-Only Scan: Avoiding Table Access” گرفته شده است.
نکته کلیدی در این مثال این است که ایندکس B-tree تمام ستونهای موردنیاز را دارد—نرمافزار پایگاه داده نیازی به دسترسی به جدول ندارد. این همان چیزی است که ما به آن اسکن تنها ایندکس میگوییم.
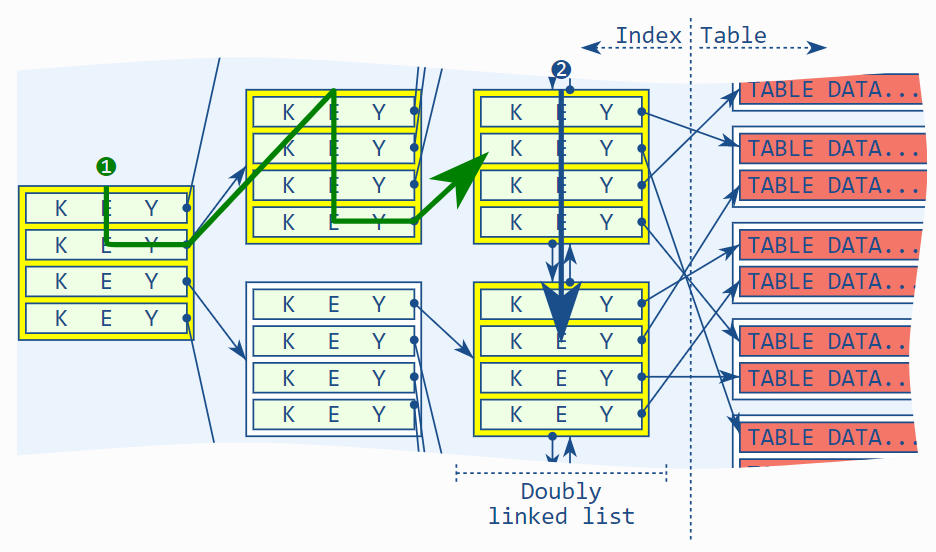
با اعمال فرمولهای بالا، اگر تعداد کمی رکورد شرایط where را برآورده کنند، مزیت عملکردی این روش بسیار کم است. از سوی دیگر، اگر عبارت where تعداد زیادی رکورد را انتخاب کند، مثلاً میلیونها، تعداد عملیاتهای خواندن اساساً با یک ضریب ۱۰۰ کاهش مییابد.
این پرسوجو همچنان میتواند از این ایندکس برای یک اسکن تنها ایندکس استفاده کند و به همین دلیل عملکرد مشابهی ارائه میدهد.
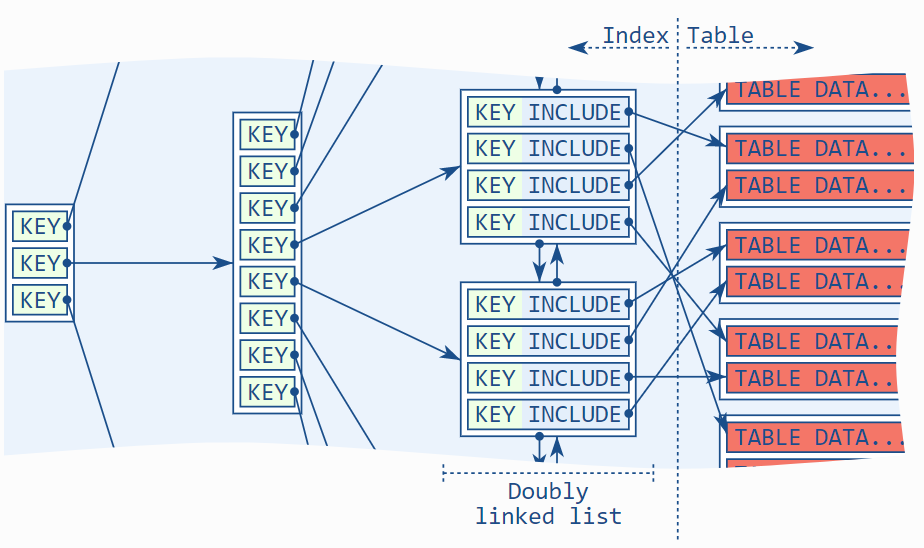
علاوه بر تفاوتهای آشکار در تصویر، یک تفاوت ظریفتر نیز وجود دارد: ترتیب ورودیهای نود برگ شامل ستونهای include نمیشود. ایندکس فقط بر اساس ستونهای کلید مرتب شده است. این امر دو پیامد دارد: ستونهای include نمیتوانند برای جلوگیری از مرتبسازی استفاده شوند و همچنین در بررسی یگانگی (uniqueness) در نظر گرفته نمیشوند.
سازگاری با پایگاهدادههای مختلف
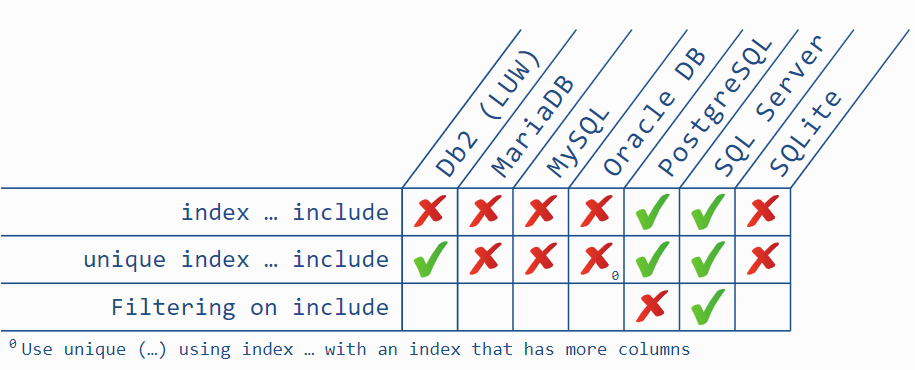
PostgreSQL: عدم فیلترگذاری قبل از بررسی مشاهدهپذیری
پایگاه داده PostgreSQL محدودیتی در اعمال فیلترها در سطح ایندکس دارد. خلاصه این است که این کار را انجام نمیدهد، مگر در چند مورد خاص. بدتر اینکه، برخی از این موارد تنها زمانی کار میکنند که داده مربوطه در بخش کلید ایندکس ذخیره شده باشد، نه در عبارت include. این بدان معناست که انتقال ستونها به عبارت include ممکن است عملکرد را کاهش دهد، حتی اگر منطق توصیفشده فوق همچنان اعمال شود.
داستان کامل با این واقعیت آغاز میشود که PostgreSQL نسخههای قدیمی ردیفها را در جدول نگه میدارد تا زمانی که برای تمام تراکنشها نامرئی شوند و فرآیند vacuum آنها را در آینده حذف کند. برای دانستن اینکه آیا یک نسخه ردیف، برای یک تراکنش مشخص قابل مشاهده است یا خیر، هر جدول دو ویژگی اضافی دارد که نشان میدهند یک نسخه ردیف چه زمانی ایجاد و چه زمانی حذف شده است: xmin و xmax. ردیف تنها در صورتی قابل مشاهده است که تراکنش جاری در محدوده xmin/xmax قرار گیرد.
متأسفانه، مقادیر xmin/xmax در ایندکسها ذخیره نمیشوند.
این بدان معناست که هر زمان PostgreSQL به یک وارده ایندکس نگاه میکند، نمیتواند تعیین کند که آیا آن وارده برای تراکنش جاری قابل مشاهده است یا خیر. ممکن است وارده حذف شده باشد یا واردهای باشد که هنوز تأیید نشده است. روش استاندارد برای فهمیدن این موضوع، نگاه کردن به جدول و بررسی مقادیر xmin/xmax است.
نتیجه این است که چیزی به نام اسکن تنها ایندکس (index-only scan) در PostgreSQL وجود ندارد. فرقی نمیکند چند ستون در یک ایندکس قرار دهید، PostgreSQL همیشه نیاز به بررسی مشاهدهپذیری دارد که در ایندکس موجود نیست.
با این حال عملیات Index Only Scan در PostgreSQL وجود دارد—هرچند که همچنان نیاز دارد مشاهدهپذیری هر نسخه ردیف را با دسترسی به دادههای خارج از ایندکس بررسی کند. به جای رفتن به جدول، Index Only Scan ابتدا نقشه مشاهدهپذیری (visibility map) را بررسی میکند. این نقشه بسیار فشرده است، بنابراین تعداد عملیات خواندن (امیدواریم) کمتر از دریافت xmin/xmax از جدول باشد. با این حال، نقشه مشاهدهپذیری همیشه پاسخ قطعی نمیدهد: نقشه مشاهدهپذیری یا اعلام میکند که ردیف قابل مشاهده است، یا اینکه مشاهدهپذیری آن مشخص نیست. در حالت دوم، Index Only Scan همچنان باید xmin/xmax را از جدول بازیابی کند (در explain analyze با عنوان “Heap Fetches” نمایش داده میشود).
پس از این توضیح کوتاه در مورد مشاهدهپذیری، میتوانیم به فیلترگذاری در سطح ایندکس بازگردیم.
SQL اجازه استفاده از عبارات پیچیده در عبارت where را میدهد. این عبارات ممکن است خطاهای زمان اجرا مانند “تقسیم بر صفر” ایجاد کنند. اگر PostgreSQL چنین عبارتی را قبل از تأیید مشاهدهپذیری ورودی مربوطه ارزیابی کند، حتی ردیفهای نامرئی نیز میتوانند باعث چنین خطاهایی شوند. برای جلوگیری از این مسئله، PostgreSQL معمولاً مشاهدهپذیری را قبل از ارزیابی چنین عبارات بررسی میکند.
یک استثنا برای این قانون کلی وجود دارد. از آنجا که مشاهدهپذیری را نمیتوان هنگام جستجوی ایندکس بررسی کرد، عملگرهایی که میتوانند برای جستجو استفاده شوند، باید همیشه امن باشند. این عملگرها همانهایی هستند که در کلاس عملگر مربوطه تعریف شدهاند. اگر یک فیلتر ساده از یک عملگر موجود در کلاس عملگر استفاده کند، PostgreSQL میتواند آن فیلتر را قبل از بررسی مشاهدهپذیری اعمال کند زیرا میداند این عملگرها ایمن هستند. نکته اینجاست که تنها ستونهای کلید یک کلاس عملگر مرتبط دارند. ستونهای موجود در عبارت include چنین کلاسی ندارند—فیلترهایی که بر اساس آنها هستند، قبل از تأیید مشاهدهپذیری اعمال نمیشوند. این برداشت من از یک بحث در mailing list توسعهدهندگان PostgreSQL است.
برای نمایش این موضوع، ایندکس و کوئری قبلی را در نظر بگیرید: